Riccardo Loggini
Render Thread Jobification
Table of Contents
Why Jobify The Render Thread
From the arrival of multithreaded programming in the video game scene (around 2010) the render thread has become a standard when talking about game engines.
Its structure is changing over the years, from first being tied to the game tread to then now be identified as a set of asynchronous tasks.
I wanted to know more about it and the latest technical advancements that can be useful to build a modern real-time renderer.
This article ended on describing more general multithreading on a game engine rather than focusing too much on render thread details: another big topic really close to this one is implementing a Render Graph, a system used to subdivide render code into optimal jobs, but it will not be mentioned here because too big to describe. Possibly in the future I will make a post dedicated to it.
In this post I will briefly go through concepts of parallel execution and patterns for a job system. The topic will then move to render threads and how modern engines are handling it. Toward the end I cite some implementations of job systems and thread pools, to then describe the most common C++ tools used to build such systems.
This article is more about concepts than code, and it can be used as a first read to get into job systems and multi-threaded engines, before an actual implementation.
Parallel Execution
When talking by parallel execution we generally mean executing two or more chunks of code concurrently.
This does not necessarily mean that we are using a CPU with multiple cores: we can execute two programs on a single computation unit, by taking turns to use it.
We can then talk about hardware threads , a name for the physical available cores on the CPU, and the software threads or simply threads, which are software constructs to organize work for the physical side.
In this context, an entire application is identified as a process , and in an application we can have one or more concurrent software threads.
Threads are considered the basic unit of execution, in the sense that code flow running on each one of them is linear.
There is then a thread scheduler that will organize the work of the software threads to be mapped into the physical ones: this process aims to keep the physical CPU cores always as busy as possible.
A (software) thread is composed by:
- Thread ID
- Program Counter: it refers to a CPU hardware register that contains the address of the instruction to execute.
- Register Set: a region of memory used to execute the instructions. They become explicit when we inspect machine code out of our C++ code.
- Stack: the call stack of the executed code, a last-in-first-out (LIFO) queue of active subroutines (function calls).
Multiple threads can then share resources (variables) which access needs to be moderated by synchronization primitives.
A thread can lock a resource, or a code region, meaning that the thread has exclusive access to it, and the other threads that want to access it will have to wait their turn.
We then can have a situation of dead lock , where two or more threads are stuck waiting for each other to release locks.
Split Work Into Jobs
When there is benefit to divide the operations on multiple threads, TripleA engines split their work into Jobs , and each of those jobs can depend on the execution of other jobs.
Jobs can then be split into independent sub-activities called Tasks.
A Task can be seen as a function call, stored into an object. They should be independent from other tasks so they can be executed in parallel, and the ideal number of tasks per each job is the number of physical threads available (or a multiple of it) so we can maximize the available hardware parallel capabilities.
Tasks are intended to run by a Task Manager that, from a user programmer point of view, can be seen as a black box where we send the task to execute as input and it will take care of the rest.
Task manager will select tasks to execute from a FIFO queue and run them by available threads from a thread pool.
The threads in the pool are called Worker Threads , and a pool usually contains a number of elements equal to the number of available CPU cores for the application.
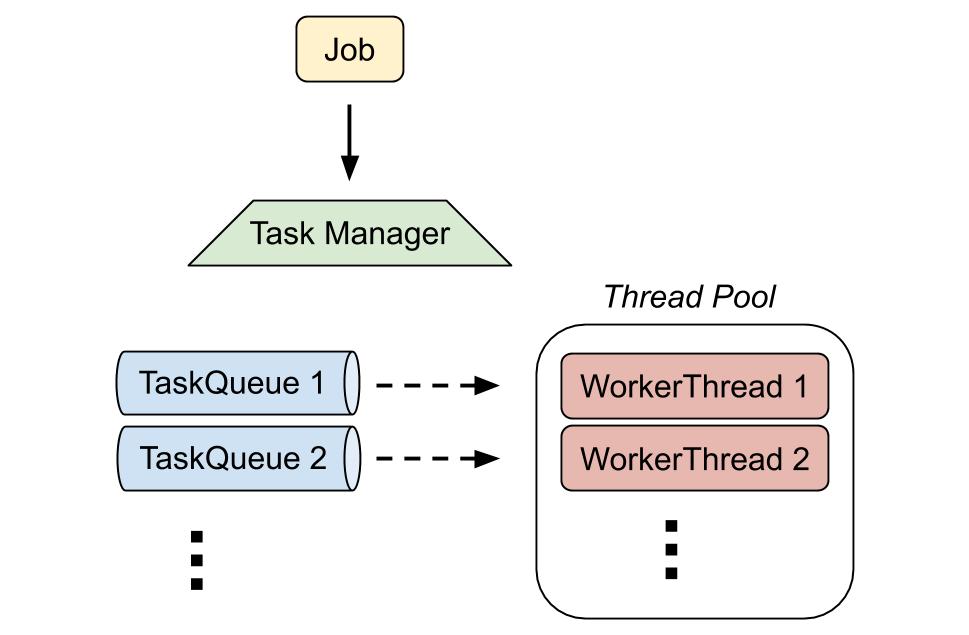
When a selected thread from the pool will execute a task the following will happen:
- Wait for task dependencies to be executed: For example, an atomic integer variable can be stored inside the task object to determine how many dependencies are left before execution. The awaited tasks will decrement this variable once they finish execution.
- Execute task work
- Signal dependent tasks that work is done: For example, a vector of tasks references is used to store the tasks waiting for the current task execution. This vector can be seen as a multicast delegate that will signal dependent tasks when work is done.
Note: the system should aim to have tasks with as few dependencies and shared data as possible in order to have the minimum waiting time when handling concurrent threads.
The advantage of using this structure is that we have a layer abstraction from the current platform and we do not have to care about referencing specific threads, or the CPU cores quantity or other hardware details.
The way we can use this system from a programming end point, is as follows:
JOB_ENTRY_POINT(MyExecuteJobFunction)
{
//...
}
void ExecuteMyJobs()
{ // Setup jobs
Job[100] myJobs;
for(i = 0 to 99; i++)
myJobs[i] = Job(&MyExecuteJobFunction, dataToWorkWith);
// Atomic counter variable returned from running jobs
Counter& jobCounter = TaskManager::RunJobs(myJobs, 100);
// Placing a task barrier
TaskManager::WaitForCounter(jobCounter, 0);
}
The WaitForCounter function will have to stall the current thread up until all the jobs will finish executing and the counter will be decreased to 0.
A design pattern like this will bring the benefit of the easiness for a job to wait for another: just call WaitForCounter().
An ideal job duration is between 500us and 2000us.
A thread pool can be implemented by using already existing APIs, for example Intel Threading Building Blocks or the many found on github. More examples about this in the Available Tools Section.
Eventually we can have multiple job queues, each with a different priority level.
For example, the simulation thread, the one that computes gameplay, needs to be executed as fast as possible so the jobs spawned by it will have high priority.
Here there is an example of thread binding subdivision for an intel i5 of 2020, having 6 physical cores:

Physical CPU threads can be mapped to specific elements of our thread pool.
The core 0, and so the relative thread, can be reserved to simulation (gameplay) jobs.
Other jobs like render and audio can be executed by medium priority threads and so by core 1, 2 and 3.
Lower priority threads, e.g. async loading or http request can take thread 5.
Still we need to consider that some cores, especially on consoles (e.g. XBox 1), can be reserved to the OS and so they are excluded from programmer usage.
Note: The standard thread libraries tend to leave the hardware thread mapping to the thread scheduler, which is supposed to optimize the execution of tasks by itself, without intervention from the programmer. Hardware thread mapping is possible by using specific libraries tied to each different OS (more info about this in the Available Tools section), so generally speaking it is recommended to first try an approach without hardware thread mapping, and then adding it at a second moment for optimization purposes.
Naughty Dog's Fibers
Once we have our job system up and running we might think to refine it. That was the case for Naughy Dog that in 2015 presented a series of parallel code patterns at GDC.
There is a number of issues we might encounter when developing a job system:
- We might want to be able to run tasks halfway through, then stop them to give precedence of execution to other tasks, and then resume them.
- The state of a job list is somewhat unknown: when we submit a job it could immediately get executed or it can stay on the waitlist for long, depending if on a specific moment, the number of jobs in the queue before it.
For this reasons the concept of Fibers comes up: it can be seen as a stripped down thread object containing:
- Stack frame to store the executing function and its argument data. It can have a size from 64 KB to 512 KB.
- State variables to use for when the fiber is put on pause.
Note: Unlike a task object, a fiber does not contain information about scheduling and thread dependencies.
Fibers are used as context of execution for a specific thread.
When we want to switch the executing fiber, we put the current one on pause, and change the thread stack pointer and program counter to the second fiber.
This operation will generate a minimal overhead in comparison to a default thread system where the context switching will be more expensive.
This form of threading is called no preemption (aka Cooperative Threads ).
If the thread pool is made with cooperative threads, a thread execution will terminate only when the thread will release itself, an operation called yeld.
There are a number of non-preemptive thread libraries already available on the web, such as the one from Boost.
Note: A drawback for a fiber design pattern is that we cannot use semaphores, mutexes or any other system primitives. This comes because the OS will tie those to the executing thread, so that when we switch over the fiber context of a thread for another fiber, the system primitives would lose meaning and provoke dead locks.
As a consequence, all the synchronization has to be made at a hardware level with custom mechanics using tools like atomic variables.
On an application breakpoint, due to the similarities with threads, we are able to inspect the callstack and variables states of a fiber. This also allows to store such information in crash reports when something goes wrong.
From user experience gathered on the web, running a non-preemptive job system like fibers is more complex to use than a preemptive job system, and should only be considered if the number task switches is creating a delay that can be seen as a performance bottleneck.
In most of the cases task switching is not the performance bottleneck. You can read about pros and cons about fibers in this article.
Express Synchronization
The following design patterns are inspired from the presentation given by Bungie's Barry Genova on game engine multithreading.
Locking resources in general is an expensive operation, and we want to minimize the number of times that this happens at runtime.
Instead of singularly locking resources, it is possible to organize the tasks into standalone layers of independent jobs, and use job dependencies.
The execution of job A that depends on job B, will happen in a separate layer that runs when job B has already finished executing.
This form of scheduling is also known as Express Synchronization.

We do not need to use fence objects but just to respect dependencies between jobs and use predefined synchronization point tasks.
The Render Thread
If we think at all the work that the engine is doing at runtime, we can express it as a straight chain of events as follows:
- Game Objects simulation: compute gameplay, this often includes AI and physics.
- Determine what to render.
- Generate and send render commands to the GPU.
- Wait for the GPU to finish execution.
- Display the results on window.
This flow works well for a single thread architecture and it is the usual flow that we see in old game engines.
When threaded programming became a standard, which is around the time of when C++11 came out, we started seeing the so called System-On-A-Thread Design , which consists in mapping physical CPU cores to specific threads.
Considering an Intel i5 from 2011 with 4 cores, this might have been the mapping:
- Core 0: used for Simulation Loop (gameplay, physics, AI, etc.)
- Core 1: used for Render Loop exclusively
- Core 2: used for Audio exclusively
- Core 4: OS taks, I/O, misc
In this way each "main chunk" of independent work could correctly carry on without having to enqueue with other independent tasks.
Render thread generally covers:
- Visibility computation : this operation is also known as Occlusion Culling (not described in this article because out of context).
- Generating/updating render proxies : converting visible scene objects state to GPU-friendly format. More about this in the next section.
- Generate and submit command buffers to the GPU and finally display the results on windows.
The Visibility Queries , made at the start of the render pipeline, will be used to determine what proxies are relevant for the drawing operations: we will not consider objects that are not visible.
Note: The visibility pass needs to take into consideration every point of view used in the scene: for example, aside from the player camera, there are also the light sources point of view to compute shadows.
Part of the visibility computation can be done in parallel with the simulation task: as soon as we know the player camera (as well as the other views) frustum position, we can compute the visibility of the static objects.
For all the moving objects, like characters or projectiles, we will have to wait for simulation to finish the current frame to know the exact objects considered for rendering.
The way work can now be subdivided is as follows:

When computing simulation for frame N+1 on the simulation thread, at the same time the render thread will compute the rendering part for the previous frame N.
To achieve that, we will always need to keep the game state data from the previous frame, effectively having double the information at the same time: one from frame N and one for frame N+1. As you can imagine, this pattern represents a substantial memory footprint cost to maintain.
Note: The advantage of having the simulation being one frame above compared to what we render is essential to make the two parts completely independent.
The human eye cannot recognize that we are rendering the previous frame instead of the current one.
Even when using this threaded approach, by inspecting the performance analyzer, we can quickly realize that half of the threads computational power was not used. For example, despite simulation and render threads being always at full load, you might have audio and misc jobs threads used for just 30% of their potential.
In addition to that, when we change the number of threads, for example at the time of writing this post (2020) the usual number of cores is 6 or more, the system will not scale well because there is going to be more and more computational power not getting used.
Render Becomes Jobs
A modern look at the render thread is not bound to a specific core anymore: rendering becomes a set of jobs with a medium priority, as we have seen in the previous section, that need to finish executing before we can present the relative frame to the screen.
Everything on the visibility and render workload gets splitted into tasks, that can be further optimized by considering the average time of each job and operate load balancing mechanics, aiming for a low latency and high CPU/GPU occupancy at every time.
Note: these are jobs for a SINGLE frame… multiple frames (and relative jobs) are being computed at the same time..
These sets of jobs get subdivided by a sequence of phases , multithreaded where possible:
- Execute in sequence:
- Simulation for frame N
- Visibility for frame N
- Proxy objects creation/update for frame N (more of this on the next section)
- In parallel to the previous one execute:
- Render commands generation and submit to GPU for frame N-1
Simulation, visibility and proxy update for the current frame will each start when the previous one finishes executing. The resulting updated proxies will be used in the next frame for the render jobs. We use well-defined Synchronization Points between one phase and another to ensure all the operations for the previous phase have been completed, and so data is safe to be accessed again, before passing to the next phase.
Synchronization Points are special kinds of jobs that will execute every frame, no matter the situation.
Render Proxy Objects
Engines like Unreal store static information about each scene object relevant for the renderer.
This is made so we can divide game mechanics, happening in game thread, from rendering, happening in the render thread.
These static information objects are called Render Proxies.
Render proxies are different from the scene objects they represent: they are much smaller in size and they contain only the relevant information of the object for being rendered.
The fundamental detail of these proxies is that their full ownership belongs to the render thread: only the render thread can edit the proxy, meanwhile the game thread will have exclusive edit capabilities of the scene object.

Proxies will reference all and only the relevant data to render game objects, but at each frame their update will consist only in dynamic data: things like world transform, skinning transforms, dynamic variables are changed on a frame basis.
On the other hand, references to meshes and materials (for example) will never change and can be treated as read-only information.
Note: Visibility stage will determine what proxies to create or enable or update for the current frame!
Proxy objects allow to organize operations on a data-driven workflow : rather than fetching data on a scene object basis, object render information of the same type is stored altogether in standalone containers, so that it will be faster to access all of them at once, having maximum cache coherency on access.
Pass Job Pipeline
Using UE4 terminology, each render feature corresponds to one or more Render Passes.
Examples of render passes are Compute volumetric clouds, fill GBuffers or Render Sky Light.
In this context, a render pass is nothing else than a set of jobs.
On simulation thread side the following will happen:
- Let simulation finish for current frame and lock it.
- Determine what objects are visible (occlusion queries)
- Extract: update render-relevant proxy objects.
- Unblock simulation to start computing the next frame
On the next frame, the render jobs will do the following:
- Prepare: Generate/Update per-pass data from the render proxies: in UE4 terminology these objects are called Draw Commands. The purpose of them is to have cache-coherent data, which is pass-specific, refining the information to draw a single element for that pass.
- Retrieve the previously computed per-pass data and generate commands for the graphics API, generally a series of well setted-up Draw and Dispatch commands.
- Send commands to the GPU.
- Notify the engine when the frame has been presented.

In this pattern, draw commands are generated on a per-frame basis, and they are discarded when the frame finishes executing. In this way objects can be allocated in a ring buffer and circularly overridden upon computing the next frames.
Each per-frame data is a Frame Packet.
Further optimization involves detecting static objects that we know are not changing draw commands upon different frames: in such cases we can cache the draw commands and just copy them over to the next frame.
Available Tools
There are already a number of job system examples on the internet, for example the one from WickedEngine, or a more recent thread pool from github.
The implementation I will personally choose for my engine is based on the presentation by Sean Parent to implement a thread pool. This presentation inspired more thread pools found on the internet, such as the one in vorbrodt blog. I have chosen that for its approach to limit the use of atomic primitives because identified as the usual bottleneck in a thread pool system.
All the job system implementations (more or less) make use of the thread tools of the standard library, available from C++11 and later versions.
Threads
The fundamental concurrency object in most of C++ applications is the std::thread and their basic usage is roughly the following:
void MyCallableFunction(MyClass InMyObj);
std::thread myThread(MyCallableFunction, inputObject);
// myThread is now running
It is important to state that the passed arguments for the function get copied into the thread internal storage so they can be accessed later on when the function gets executed.
Note: If we are passing references to the thread constructor, we will have to wrap them with std::ref(..) otherwise the thread will generate and store a copy of the referenced object!
The parameter-passing semantics of the std::thread are similar to std::bind a function that will be used later on when talking about std::packaged_task.
Once the thread has started, we can call join() to generate a stall to wait for it to finish execution.
We can call detach() on a std::thread which will cause the thread to run in the background and to be handled exclusively by the C++ runtime library.
From the moment detach() gets called, it will be impossible for the user programmer to retrieve the corresponding thread object again, including using relative operations such as join().
This mechanic can come useful in situations like closing the application but still wanting the ongoing tasks to finish.
In such a case we can either call join() effectively stalling the application upon closure, or we can call detach() instead so the application will close immediately and the ongoing tasks will still run in the background, hopefully finishing in a sensible amount of time.
Note: A general opinion is that threads running after main ends is extremely dangerous and toxic. Calling detach() is something that should not be taken lightly and reserved only in specific cases and only when the programmer knows exactly what they are going (which corresponds to the 1% of the cases).
Note: Upon closing the application, if we do not call join or detach, the application can close before the threads get destroyed. In such case one of those threads can use outdated pointers referring to the shut down application, leading to potential big faults. So always make sure threads are detached or joined.
We can ensure a thread gets joined by using a Resource Acquisition Is Initialization (RAII) pattern, which consists in checking if the thread is joinable and eventually call join in the destructor.
~MyThreadClass() {
if(m_Thread.joinable())
m_Thread.join();
}
Another quite common function that we see from a thread object is the yeld() function. This function sends a "hint" to the thread scheduler saying that at the moment, the thread is not doing anything particular and can be taken to compute something else.
The common use case for yeld() is on a waiting or countdown loop.
while(true) {
if(!IsConditionMet)
Thread::yield();
}
That is why yeld() can be seen as a waiting/sleeping function, since the thread can stop the current execution for doing something more important. Still, what happens at that moment depends on the scheduler and the programmer loses control over it.
To have an idea of the available hardware threads for our application we can call the function std::thread::hardware_ concurrency(), still the returned value should only be considered as a hint since the OS has the last voice on threads availability.
Futures
We can use Future objects (since C++11) as a form of communication between tasks.
Conceptually speaking, it is like slicing a function from its result, where the Future object represents the result, appearing some time later.
Given a function that returns a type T, we can create an object with the template std::future<T> that represents the returned value of our function when it finishes executing.
Such value can be retrieved by calling get() from the future object, which effectively stalls the program until the referenced function finishes executing.
std::future<uint32_t> futureValue = std::async([]{ return CreateAndExecuteJobs(); });
std::future<void> onAsyncFuncEnds = futureValue.then([](std::future<uint32_t> inFunc){ std::cout << InFunc.get() << std::endl; });
// Async function is running, we can do something useful here.
//After that we wait for the async function to end.
onAsyncFuncEnds.wait();
We can use the type std::async by itself (without creating a thread) as the most convenient and direct way to execute an asynchronous task, as it returns a future object.
The downside of it is that we have very little control on the execution: we cannot be sure if the function gets executed serially or in another thread.
Blocking on std::future.get() has two problems:
- One thread resource is consumed, increasing contention. it can cause deadlocks: if we have a single task queue available (like a single-threaded system), and task A generates and enqueues a second task B, task A waits on a get() but it will stall the entire thread and the task B will never execute.
- Any subsequent non-dependent calculations on the task are also blocked.
Note: To prevent deadlocks, never use std::future.get() or std::future.wait() when the produced task will be executed on the same task queue as the originating code.
The current C++ standard library does Not include two very useful concepts tied to Futures, taken from Sean Parent’s Concurrency:
- Continuation: available in boost library future::then() with the member function, allows to start another task when the future state object is ready.
-
Task Joins: when a set of tasks ends (at some point in time) then start another task, without blockings. This is achieved by taking count of the routines that still need to finish, and then when we reach 0, execute the remaining operation. An example of this can be found with the function from boost library when_all.
- Task Split: when a task ends then start a series of parallel tasks (without using blocking mechanics).
Packaged Tasks
An alternative over std::async is using objects of templated type std::packaged_task.
Packaged tasks store a function to execute and return a future like std::async, but the difference is that we have control over when we run it: we can create a standalone package first, and then execute it on a thread at a later stage.
std::packaged_task<int(double, char, bool)> myTask(myFunction);
std::future<int32_t> myFutureValue = myTask.get_future();
// Then later on…
std::thread thr(std::move(myTask), inputValue1, inputValue2);
// Retrieve the result of the future as before
int32_t returnedValue = myFutureValue.get();
Promises
An object of type std::promise is the sending side of a future.
Whenever we are calling get() from std::future, internally, it waits until the owner of the corresponding std::promise to finish computing the returned value and then calls set_value().
From when we call get_future() from a promise, the following will happen:
- the promise object is considered the asynchronous provider and it is expected to call set_value() for the shared state with the future.
- the future object is considered the asynchronous return object, that can retrieve the value from the shared state with the promise, waiting for it to be ready if necessary.
The purpose of this separation is to ensure that the code that receives the result of the async task is completely separated from the code that computed the task.
The following example usage has been taken from modernescpp.com:
void product(std::promise<int>&& intPromise, int a, int b){
// Simulates the execution of the task (just the product a*b) and calls set_value on the promise
intPromise.set_value(a*b);
}
int main(){
std::promise<int> prodPromise;
std::future<int> prodResult= prodPromise.get_future();
// From here future and promise are bound to the same shared data
// Calculate the result in a separate thread
std::thread prodThread(product,std::move(prodPromise), 20, 10);
// get the result (note: this will stall the current thread until the result arrives)
std::cout << "20*10= " << prodResult.get() << std::endl;
// Make the thread finish and join it with the current one
prodThread.join();
}
Note: the shared state between a promise and a future lives until the last object is destroyed, meaning that if a promise gets destroyed, we can still retrieve the value from the associated future.
If the promise object get destroyed before calling set_value(), the corresponding future object will generate an std::broken_promise exception when trying to get the value.
Still, we can use promise objects to handle async tasks at the lowest level.
Atomic Variables
Atomic variables in C++ are almost always a way to indicate objects of templated type std::atomic, a type for which multiple threads can edit it without raising undefined behavior.
Preventing undefined behavior in this context means to prevent data race conditions, so that all the read and write operations are executed in a specific sequential order.
std::atomic<uint64_t> lastFinishedTaskNum;
// ..then later when the task finishes..
lastFinishedTaskNum.fetch_add(1);
// ..on another thread we can check the number of finished tasks up until now
if( lastFinishedTaskNum.load() > numToCheck )
{ /* ..do something.. */ }
The generic way to change the value of an atomic variable is to use the member function store(..) but in a thread pool context is also common to use the function fetch_add(..) which is a store that takes into consideration the previous value and uses the arithmetic addition ("+" operator) of the stored type.
As very well explained in this stackoverflow thread, a more low level usage of the store operations is also specifying the memory order type :
std::memory_order_seq_cstis the default one, and ensure sequential consistency of all the atomic operations on a variable.std::memory_order_releaseis an optimization for the store() operation, which consists on a release: the system assumes that this was the last operation on the variable for the current thread and no other reads or writes will be ordered for the current thread. All the atomic writes in the current thread will be visible on other threads that atomically read the variable.std::memory_order_acquireis an optimization for the load() operation: no reads or writes to the variable will be ordered before this load for the current thread. All the atomic writes from the other threads will be visible in the current thread when it atomically reads the variable.
Mutex, Condition Variable and Lock Guard
Another tool that we have from the C++11 standard library is the combination of the synchronization primitive std::mutex and std::condition_variable types.
A mutex can be used to prevent shared data from being accessed by multiple threads without correct ordering of operations, while the condition variable can generate signals to communicate between threads.
Note: From C++17 instead of
std::lock_guardwe can usestd::scoped_lock.
The difference between std::unique_lock and std::lock_guard is that we can lock and unlock a unique_lock at our will, meanwhile lock_guard will unlock when it gets destroyed (so most of the time, when the scope ends). That is also why perform a wait on a std::condition_variable we need a std::unique_lock.
The following example is heavily inspired by an article by thispointer.com where you can find also the code example.

In this example thread 1 wants to perform operations with some data that needs to be loaded. The strategy here is running a second thread in charge of loading the data, meanwhile the first thread can execute other initial operations.
When the first thread is ready to handle the loaded data, it will call wait on the condition variable, and this will execute the following:
- Release the acquired lock.
- Put the thread to sleep up until the condition on the wait gets satisfied.
Note: the condition on the condition variable is totally optional. It will make the thread to loop until the condition is satisfied, but we can use the condition variable without it!
Then the second thread will load the data, and acquire the lock.
When it succeeds, it will set the variable for the condition (in this case isDataLoaded) to true, and finally calls notify_one on the condition variable.
This last action has the following effects
- Wakes up a single thread waiting on the condition variable.
- The woken up thread will attempt to re-acquire the lock and continue execution from where it was waiting.
Note: the notify will Not release the lock! We need to manually release it or we need to wait for that lock to release itself (e.g. going out of scope)!
Calling the function notify_one() on the condition variable will signal a single thread waiting for such condition, while calling notify_all() will notify all of them. It is important to note than when calling notify, if the woken up thread will find the condition to not be satisfied, it will turn back to sleep.
Platform Specific Tools
The operative system can also give a number of functionalities for multithreading which can get closer to hardware.
I will just briefly mention the \<Windows.h\> library, that among other things, it allows to state a thread (but also an entire process) Affinity Mask , to decide what physical core will execute each of our threads.
The following code assigns one thread per core (credit to this stackoverflow thread):
std::vector<std::thread> threads;
for (unsigned int i = 0; i < std::thread::hardware_concurrency(); ++i)
{
DWORD_PTR dw = SetThreadAffinityMask(threads.back().native_handle(), DWORD_PTR(1) << i);
if (dw == 0)
{
DWORD dwErr = GetLastError();
std::cerr << "SetThreadAffinityMask failed, GLE=" << dwErr << '\n';
}
}
Profile Parallelization
For Windows Visual Studio environment, I recommend trying out Concurrency Visualizer, an extension that plots information about thread activity.

Concurrency Visualizer also supports using markers via the Event Tracing for Windows (ETW).
You can read an introductory guide also from Paul Freedman’s Blog.
Other than the classic Visual Studio integrated tools, at the time of writing this post the most recommended tool to debug parallel code in both Windows and Linux is the Intel VTune Profiler.
Vtune is ofcourse specialized in Intel CPUs but it also supports AMD ones.
Sources
-
The Poor Man's Threading Architecture - Gamasutra
https://www.gamasutra.com/blogs/EvanTodd/20160113/263423/The_Poor_Mans_Threading_Architecture.php -
Destiny's Multithreaded Rendering Architecture
https://www.youtube.com/watch?v=0nTDFLMLX9khttp://advances.realtimerendering.com/destiny/gdc_2015/Tatarchuk_GDC_2015__Destiny_Renderer_web.pdf
-
Multithreading the Entire Destiny Engine
https://www.youtube.com/watch?v=v2Q_zHG3vqg -
Task-based Multithreading
https://www.gdcvault.com/play/1012321/Task-based-Multithreading-How-to -
Naughy Dog Parallelization (2015)
https://www.gdcvault.com/play/1022186/Parallelizing-the-Naughty-Dog-Engine -
Wicked Engine - Job System
https://wickedengine.net/2018/11/24/simple-job-system-using-standard-c/ -
Intro to Threads - Neso Academy
https://www.youtube.com/watch?v=LOfGJcVnvAk -
Multi-threaded programming Part A - BogoToBogo
https://www.bogotobogo.com/cplusplus/multithreaded4_cplusplus11.php -
Stack Exchange - Thread Pool Discussion
https://codereview.stackexchange.com/questions/221617/thread-pool-c-implementation -
Better Code: Concurrency - Sean Parent
https://www.youtube.com/watch?v=zULU6Hhp42w -
Advanced thread pool - vorbrodt blog
https://vorbrodt.blog/2019/02/27/advanced-thread-pool/ -
Various StackOverflow threads
https://stackoverflow.com/questions/11004273/what-is-stdpromise/12335206#12335206 and https://stackoverflow.com/questions/12620186/futures-vs-promises -
Locks and Condition Variables - CS 140 - Stanford University
https://web.stanford.edu/~ouster/cgi-bin/cs140-spring14/lecture.php?topic=locks -
Paul Freedman - Gaining Intuition on Multi-Threading
https://medium.com/@paul.freedman19/gaining-intuition-on-multi-threading-with-visual-studio-concurrency-visualizer-40414548de7c -
C++ Concurrency In Action - Anthony Williams
https://www.manning.com/books/c-plus-plus-concurrency-in-action-second-edition